The post App Bocconi Avvelenati first appeared on Oimmei Digital Consulting.
]]>È nata come evoluzione dell’IZS, ovvero l’Istituto Zooprofilattico Sperimentale del Lazio e della Toscana, che aveva creato un portale focalizzato sugli avvelenamenti dolosi nel 2019. Dopo averla scaricata, gli utenti devono registrare il loro profilo per garantire rintracciabilità, una misura fondamentale per evitare segnalazioni non veritiere che potrebbero sovraccaricare il sistema.
Gli utenti hanno la possibilità di inviare una foto dell’esca sospetta, consentendo anche la geolocalizzazione.
Come funziona Bocconi Avvelenati Il funzionamento dell’app Bocconi Avvelenati si basa sulle segnalazioni dei cittadini che, dopo essersi registrati, possono segnalare la presenza di un’esca sospetta caricando una foto.
Questa procedura attiva l’allarme presso i servizi veterinari e il Sindaco della regione interessata, affinché i nuclei cinofili dei Carabinieri possano effettuare un’ispezione nella zona segnalata.
L’applicazione rappresenta un efficace sistema di prevenzione, permettendo ai proprietari di cani o gatti di consultare la mappa e verificare la presenza di potenziali pericoli per i loro animali grazie alle segnalazioni ricevute.
Il Ministero della Salute ha dichiarato che il fenomeno delle esche avvelenate rappresenta un “problema di sanità e incolumità pubblica in quanto, oltre a rappresentare un rischio per gli animali domestici e selvatici, comprese le specie in via d’estinzione, costituisce un grave pericolo per l’ambiente e per l’uomo, in particolare per le categorie più a rischio quali i bambini”.
Qua il link all’Istituto Zooprofilattico Sperimentale del Lazio e della Toscana da dove scaricare l’App
(Foto di Pauline Loroy su Unsplash)
The post App Bocconi Avvelenati first appeared on Oimmei Digital Consulting.
]]>The post Sviluppo software di successo e benefici per la tua azienda first appeared on Oimmei Digital Consulting.
]]>Immagina di avere l’esigenza di gestire in modo efficace i lead generati dalle attività di marketing e vendita. Potresti aver bisogno anche di automatizzare il funzionamento di complessi macchinari, rendendo l’operatività più fluida ed efficiente. Allo stesso modo, potresti aspirare a creare un’applicazione che ottimizzi l’interazione dei tuoi clienti con il tuo business, migliorando l’esperienza complessiva.
Lo sviluppo software abbraccia un vasto insieme di attività informatiche, dalle fasi iniziali di ideazione e progettazione, fino alla distribuzione e al supporto continuativo del software stesso. Questo processo sottolinea l’importanza cruciale di creare soluzioni su misura che soddisfino le esigenze specifiche dell’azienda e contribuiscano al suo successo a lungo termine.

Quali sono le ragioni per investire nello sviluppo di software personalizzato per la tua impresa?
Nel mondo sempre più digitale di oggi, l’investimento nello sviluppo software di applicazioni informatiche personalizzate sta diventando sempre più cruciale per le aziende che mirano a rimanere competitive e innovative. Ma quali sono le ragioni fondamentali per cui dovresti considerare seriamente questa opzione? Ecco alcuni motivi convincenti per investire nello sviluppo software aziendale su misura per la tua impresa.
Adattamento alle Esigenze Aziendali: Ogni azienda ha esigenze e processi unici. Le soluzioni software preconfezionate potrebbero non soddisfare appieno le tue esigenze specifiche. Investire in software personalizzato ti consente di creare un’applicazione su misura che si integra perfettamente con i tuoi processi operativi e ottimizza le tue attività.
Vantaggio Competitivo: Lo sviluppo di software personalizzato può conferirti un vantaggio competitivo significativo. Puoi creare funzionalità uniche e soluzioni innovative che differenziano la tua azienda dai concorrenti. Questo non solo attira l’attenzione dei clienti, ma può anche migliorare la tua posizione nel mercato.
Efficienza Operativa: Il software personalizzato è progettato appositamente per rispondere alle esigenze dell’azienda. Questo significa che può migliorare l’efficienza operativa, semplificando processi complessi, automatizzando attività ripetitive e riducendo gli errori umani. Una maggiore efficienza si traduce in risparmio di tempo e risorse.
Controllo e Flessibilità: Con il software personalizzato, hai il pieno controllo sulle funzionalità e le caratteristiche dell’applicazione. Puoi apportare modifiche e aggiornamenti in base alle tue esigenze in continua evoluzione, senza dover aspettare le versioni successive dei prodotti commerciali.
Sicurezza Migliorata: La sicurezza dei dati è una preoccupazione prioritaria per qualsiasi azienda. Le soluzioni software personalizzate possono essere dotate di misure di sicurezza su misura per proteggere i tuoi dati sensibili e ridurre il rischio di violazioni.
Supporto Continuo: La collaborazione con un team di sviluppatori per lo sviluppo di software personalizzato può offrire un supporto continuo. Dopo il lancio, l’azienda può fornire manutenzione, risolvere eventuali problemi e apportare aggiornamenti in modo tempestivo.
Rendimento a Lungo Termine: Sebbene l’investimento iniziale possa sembrare considerevole, il software personalizzato può generare rendimenti a lungo termine. Migliorando l’efficienza e l’efficacia delle tue operazioni, il software può contribuire a un aumento della produttività e dei profitti nel tempo.
L’investimento nello sviluppo di software personalizzato offre una serie di vantaggi chiave per le aziende moderne. Dall’adattamento alle esigenze specifiche, al vantaggio competitivo, all’efficienza operativa e alla sicurezza migliorata, questa opzione può rappresentare un passo strategico per il successo dell’impresa nel panorama digitale in continua evoluzione.
Cosa vuol dire sviluppare un software
Nel panorama aziendale odierno, molte imprese hanno già sviluppato o sono in fase di sviluppo delle proprie applicazioni, mirando ad aumentare la loro competitività sul mercato. Mentre tutti riusciamo a riconoscere l’aspetto di un’applicazione, spesso ci sfugge ciò che si cela dietro di essa. Qual è il lavoro che richiede la sua creazione? Questo processo è chiamato sviluppo software.
L’attività di sviluppo software rappresenta un intero ciclo che coinvolge numerose fasi cruciali nella creazione di un programma informatico.
Quando parliamo di “software“, ci riferiamo all’insieme di istruzioni che consentono all’hardware (sia esso un computer, un tablet o uno smartphone) di eseguire una specifica operazione. Queste istruzioni vengono fornite attraverso algoritmi, che spiegano al dispositivo cosa deve fare per risolvere un determinato problema.
Una volta compreso il concetto di software, il termine “sviluppo” si riferisce al processo complessivo che include l’analisi dell’idea e delle premesse, la progettazione tecnica, la scrittura del codice tramite programmazione informatica, seguita dalla fase di test per individuare e correggere eventuali bug e errori, culminando infine nel lancio del prodotto.
Nel mondo aziendale, esistono svariate tipologie di software, ciascuna pensata per diverse finalità. Questi vanno dai programmi per la gestione dei dati a quelli dedicati alla contabilità. Ad esempio, un software per l’analisi dei dati deve essere in grado di individuare, visualizzare, archiviare e calcolare dati aziendali, trasformandoli in grafici comprensibili. Inoltre, deve accedere alle informazioni su clienti, prodotti, reparti e molto altro ancora.
DI seguito una panoramica su alcune tipologie di software:
- Applicazioni Web: Software accessibile tramite browser web che offre una varietà di funzionalità, come gestione dei dati, e-commerce, servizi di prenotazione e altro ancora.
- Applicazioni Mobili: App per dispositivi mobili (smartphone e tablet) sviluppate per piattaforme come iOS e Android, che possono includere giochi, strumenti di produttività, app di social media e altro ancora.
- Software di Gestione Aziendale: Soluzioni per la gestione di processi aziendali come risorse umane, contabilità, logistica, gestione delle forniture e altro ancora.
- Sistemi CRM (Customer Relationship Management): Software che aiuta a gestire le relazioni con i clienti, tracciando le interazioni, i dati di contatto, le vendite e altre informazioni pertinenti.
- Software ERP (Enterprise Resource Planning): Applicazioni integrate per la gestione di risorse aziendali come inventario, acquisti, produzione, distribuzione e finanza.
- Software di Analisi Dati: Strumenti per analizzare grandi quantità di dati e generare report utili per prendere decisioni informate.
- Software di Pianificazione di Progetti: Applicazioni per la pianificazione, gestione e monitoraggio di progetti, assegnazione di risorse e collaborazione.
- Piattaforme E-commerce: Software per la creazione di negozi online, che comprende funzioni come gestione delle transazioni, cataloghi di prodotti, carrelli della spesa e pagamenti.
- Software per la Gestione delle Risorse Umane: Applicazioni per la gestione delle informazioni e delle attività legate al personale, come assunzioni, formazione, valutazione delle prestazioni e altro ancora.
- Software per l’Automazione dei Processi Aziendali: Strumenti per automatizzare processi ripetitivi e manuale all’interno dell’azienda, migliorando l’efficienza e riducendo gli errori.
- Software per la Gestione dei Progetti Agile: Piattaforme per la gestione di progetti utilizzando metodologie agili, come Scrum o Kanban, per promuovere la collaborazione e il progresso continuo.
- Software per la Salute e il Benessere: Applicazioni per il monitoraggio della salute personale, l’esercizio fisico, la nutrizione e altre abitudini per il benessere.
- Software per l’E-learning: Piattaforme per la formazione e l’istruzione online, che possono includere corsi, quiz, materiali didattici e strumenti di valutazione.
- Software per la Gestione dei Documenti: Soluzioni per l’organizzazione, l’archiviazione e la condivisione di documenti e file all’interno dell’azienda.
- Software di Simulazione e Modellazione: Strumenti per la creazione di modelli e simulazioni di situazioni complesse, spesso utilizzati in settori come l’ingegneria e la ricerca.
- Software di Automazione Industriale: Applicazioni per controllare e automatizzare processi industriali e di produzione.
Tuttavia, il processo di sviluppo software va oltre la semplice creazione di un’applicazione. È un viaggio articolato che richiede competenze specializzate e un impegno costante al fine di realizzare prodotti di alta qualità.
Qual è la differenza tra sviluppo software e sviluppo web
Nel mondo dell’informatica e della tecnologia, i termini “sviluppo software” e “sviluppo web” sono spesso utilizzati in modo intercambiabile, ma rappresentano due concetti distinti con sfumature specifiche. Comprendere le differenze tra di essi è fondamentale per affrontare progetti in modo mirato e ottenere risultati ottimali. Ecco una panoramica delle distinzioni chiave tra lo sviluppo software e lo sviluppo web.
Sviluppo Software:
Lo sviluppo software è un termine generale che si riferisce alla creazione di applicazioni informatiche, programmi e soluzioni che possono essere eseguiti su diversi dispositivi, come computer, smartphone o tablet. Questo campo abbraccia una vasta gamma di attività, dalle applicazioni mobili ai software aziendali, dai videogiochi ai sistemi operativi. L’obiettivo principale dello sviluppo software è quello di creare applicazioni che risolvano problemi specifici o soddisfino determinate esigenze.
Lo sviluppo software coinvolge la progettazione, la scrittura del codice, i test e la distribuzione dell’applicazione. Gli sviluppatori software utilizzano una varietà di linguaggi di programmazione, strumenti e tecnologie per creare soluzioni che possono funzionare offline o online. Un’applicazione desktop, un software di gestione aziendale o un gioco per console sono esempi di progetti che rientrano nel campo dello sviluppo software, ma non necessariamente implicano la connessione a Internet.
Sviluppo Web:
Lo sviluppo web, d’altra parte, è una sottocategoria specifica dello sviluppo software. Si concentra sulla creazione di applicazioni, siti web e servizi che sono accessibili tramite il browser Internet. Questo settore è strettamente legato all’interfaccia utente e all’esperienza dell’utente su Internet. Gli sviluppatori web utilizzano linguaggi di programmazione come HTML, CSS e JavaScript per creare pagine web interattive, piattaforme e-commerce, social media e altre applicazioni web.
Lo sviluppo web include anche la progettazione responsiva, che assicura che il sito o l’applicazione sia ottimizzata per diversi dispositivi e dimensioni dello schermo. Inoltre, l’aspetto della connettività è cruciale nello sviluppo web, poiché le applicazioni web richiedono un accesso costante a Internet per funzionare correttamente.
In sintesi, la principale differenza tra sviluppo software e sviluppo web sta nell’ambito delle applicazioni create e nell’accesso ai dispositivi. Mentre lo sviluppo software è un termine ombrello che copre una vasta gamma di applicazioni informatiche, lo sviluppo web si concentra esclusivamente sulla creazione di applicazioni accessibili tramite browser. Entrambi i campi richiedono competenze tecniche, ma le sfumature delle loro applicazioni influiscono sulle scelte dei linguaggi di programmazione, delle tecnologie e dei processi utilizzati dagli sviluppatori.
Come puoi notare, pur essendo due concetti distinti, entrambi hanno grande valore per le aziende che aspirano a distinguersi nell’ambito digitale.
Quale linguaggio si usa per sviluppare un software
Ma come sviluppare un software? Nell’ambito della realizzazione software, si fa largo uso di una varietà di linguaggi, scelti in base ai requisiti del sistema e alle competenze dei programmatori coinvolti. Tra quelli attualmente più diffusi figurano:
- Java: Un linguaggio versatile e multi-piattaforma ampiamente utilizzato per lo sviluppo di applicazioni web, applicazioni mobili (Android), sistemi distribuiti e altro ancora.
- Python: Conosciuto per la sua semplicità e flessibilità, Python è spesso utilizzato nello sviluppo web, nell’analisi dei dati, nell’intelligenza artificiale e nell’automazione dei processi.
- JavaScript: Utilizzato principalmente per lo sviluppo web, JavaScript è fondamentale per l’interazione dinamica e l’interfaccia utente nei browser.
- C#: Questo linguaggio è particolarmente popolare nello sviluppo di applicazioni Windows, giochi e app mobili tramite la piattaforma .NET.
- C++: Apprezzato per la sua efficienza e flessibilità, C++ è utilizzato in settori come il gaming, l’automazione industriale, l’elaborazione di immagini e altro ancora.
- PHP: Ampiamente utilizzato per lo sviluppo di applicazioni web e siti dinamici, PHP è spesso combinato con HTML per creare pagine web interattive.
- Ruby: Conosciuto per la sua semplicità e leggibilità, Ruby è spesso utilizzato con il framework Ruby on Rails per lo sviluppo rapido di applicazioni web.
- Swift: Il linguaggio di programmazione principale per lo sviluppo di applicazioni su piattaforma iOS e macOS, noto per la sua performance e la sua sintassi moderna.
- Kotlin: Utilizzato principalmente per lo sviluppo di app Android, Kotlin è apprezzato per la sua chiarezza e per migliorare la produttività degli sviluppatori.
- TypeScript: Una variante di JavaScript che offre tipizzazione statica e altre caratteristiche aggiuntive, spesso usata per sviluppare applicazioni web complesse.
- Go (Golang): Un linguaggio sviluppato da Google noto per le sue prestazioni elevate e l’efficienza nell’elaborazione concorrente.
- SQL: Sebbene sia un linguaggio di query piuttosto che di programmazione, SQL è ampiamente utilizzato per la gestione e l’interrogazione dei database
- Scala: Un linguaggio che combina caratteristiche di programmazione funzionale e orientata agli oggetti, spesso utilizzato per progetti complessi e scalabili.
- R: Utilizzato prevalentemente nell’analisi dei dati e nell’elaborazione statistica, R è apprezzato per la sua vasta gamma di librerie specializzate.
- Perl: Spesso usato per l’automazione dei processi, la gestione di testi e l’elaborazione dei dati.
- Objective-C: Un linguaggio utilizzato principalmente prima dell’introduzione di Swift, noto per essere il linguaggio principale per lo sviluppo su piattaforma iOS.
Dunque, la scelta è ampia e aziende specializzate possono suggerire la soluzione e l’implementazione software più idonea in base alle tue esigenze specifiche. L’obiettivo è creare un prodotto su misura che soddisfi appieno le tue necessità.
Le fasi del processo di sviluppo software
Lo sviluppo software è un processo complesso e strutturato che porta alla creazione di applicazioni informatiche e software su misura. Questo processo coinvolge diverse fasi che sono cruciali per garantire la realizzazione di prodotti di alta qualità e funzionalità. Esaminiamo le fasi chiave che compongono il processo di sviluppo software.
Analisi dei requisiti: Questa è la fase iniziale, in cui vengono raccolti e compresi i requisiti del software. Gli sviluppatori lavorano a stretto contatto con gli stakeholder per identificare le esigenze e le funzionalità richieste. Questa fase stabilisce le basi per il progetto.
Progettazione: Una volta compresi i requisiti, si passa alla progettazione del software. Questa fase definisce l’architettura complessiva del sistema, suddividendo le funzionalità in moduli e definendo le interazioni tra di essi. La progettazione è essenziale per garantire che il software sia scalabile, manutenibile ed efficiente.
Sviluppo: Durante questa fase, gli sviluppatori scrivono il codice effettivo del software in base alle specifiche e al design stabiliti nelle fasi precedenti. Vengono utilizzati linguaggi di programmazione e strumenti appropriati per tradurre le idee in realtà. Il codice è soggetto a revisioni continue per assicurare la qualità.
Test: Dopo lo sviluppo, il software viene sottoposto a rigorosi test per identificare bug, errori e problemi di prestazioni. Questa fase aiuta a garantire che il software funzioni come previsto e soddisfi i requisiti stabiliti all’inizio. I test possono includere il testing delle unità, il testing di integrazione e il testing dell’intero sistema.
Rilascio: Una volta superati con successo i test, il software è pronto per il rilascio. Viene distribuito agli utenti finali o implementato all’interno dell’ambiente aziendale. Il rilascio può essere fatto in una singola volta o in diverse fasi, a seconda delle esigenze dell’azienda.
Manutenzione e Aggiornamenti: Dopo il rilascio, il software richiede manutenzione continua. Gli sviluppatori monitorano le prestazioni e risolvono eventuali bug o problemi emersi nell’uso reale. Inoltre, possono essere sviluppati aggiornamenti per migliorare le funzionalità esistenti o aggiungere nuove caratteristiche.
Fine del ciclo di vita: A un certo punto, il software può raggiungere la fine del suo ciclo di vita. Questo può accadere quando non è più necessario o quando nuove tecnologie richiedono una riscrittura completa. In questa fase, il software può essere ritirato o sostituito da una nuova versione.
In conclusione, il processo di sviluppo software è un percorso articolato che richiede pianificazione, competenza e attenzione ai dettagli. Ogni fase è essenziale per garantire che il software sia funzionale, affidabile e allineato alle esigenze degli utenti e dell’azienda.

Perché un’azienda dovrebbe sviluppare un software
Nel panorama aziendale sempre più digitalizzato, lo sviluppo software ha assunto un ruolo di primaria importanza per le aziende che desiderano mantenere un vantaggio competitivo e ottimizzare le proprie operazioni. Ma quali sono le ragioni fondamentali per cui un’azienda dovrebbe investire nello sviluppo di software personalizzato?
Innanzitutto, uno dei motivi principali è l’adattamento alle esigenze specifiche dell’azienda. Ogni impresa ha processi, workflow e requisiti unici, che spesso non possono essere soddisfatti da soluzioni software preconfezionate. Lo sviluppo di un software su misura consente di creare un’applicazione che si allinea perfettamente con le operazioni e i processi interni, migliorando l’efficienza e la produttività complessiva.
Inoltre, lo sviluppo software offre la possibilità di ottenere un vantaggio competitivo tangibile. L’implementazione di un’applicazione personalizzata può consentire all’azienda di offrire servizi o funzionalità uniche che la differenziano dai concorrenti. Questo non solo attira l’attenzione dei clienti, ma può anche migliorare la percezione del marchio e la fedeltà dei clienti.
La flessibilità è un altro aspetto cruciale. Le aziende cambiano e si evolvono nel tempo, e il software dovrebbe essere in grado di adattarsi a tali cambiamenti. Con un software personalizzato, è possibile apportare modifiche e aggiornamenti secondo necessità, senza dover aspettare i tempi e le limitazioni di un prodotto commerciale.
La sicurezza è una preoccupazione sempre crescente nell’ambiente digitale odierno. Le soluzioni software preconfezionate potrebbero non garantire il livello di sicurezza necessario per proteggere i dati sensibili dell’azienda e dei clienti. Sviluppando internamente un’applicazione, è possibile implementare misure di sicurezza su misura, riducendo i rischi di violazioni e accessi non autorizzati.
Infine, lo sviluppo software può rappresentare un investimento a lungo termine. Anche se l’iniziale impegno finanziario potrebbe sembrare elevato, i benefici nel tempo possono ampiamente superare i costi iniziali. Un software ben sviluppato può migliorare l’efficienza operativa, ridurre i costi, aumentare la redditività e favorire la crescita dell’azienda nel lungo periodo.
In sintesi, lo sviluppo software su misura offre numerosi vantaggi alle aziende, dall’adattamento alle esigenze specifiche, al vantaggio competitivo, alla flessibilità, alla sicurezza e agli impatti a lungo termine. Investire in un software personalizzato è un passo strategico che può guidare le aziende verso una maggiore efficienza, innovazione e successo nel mercato sempre più digitalizzato.
A quale azienda rivolgersi per lo sviluppo di un software
Nel mondo aziendale in continua evoluzione, l’importanza dello sviluppo software su misura non può essere sottovalutata. Creare un’applicazione personalizzata che soddisfi le esigenze specifiche di un’azienda può portare a miglioramenti significativi in termini di efficienza operativa e vantaggio competitivo. Tuttavia, la scelta dell’azienda giusta per gestire questo processo è fondamentale per il successo del progetto. Ecco alcune considerazioni da tenere in mente quando si cerca l’azienda sviluppo software ideale.
- Competenza e Esperienza: Il primo aspetto da valutare è la competenza e l’esperienza dell’azienda. Cerca un team di sviluppatori con una solida conoscenza dei linguaggi di programmazione, delle tecnologie e dei framework più recenti. La presenza di un portafoglio di progetti precedenti può offrire un’indicazione chiara delle capacità dell’azienda.
- Specializzazione: Ogni azienda può avere competenze e specializzazioni diverse. Assicurati che l’azienda che stai considerando abbia esperienza nello sviluppo di software simili a quello che stai cercando. Ad esempio, se desideri un’applicazione mobile, cerca un’azienda con competenze specifiche nello sviluppo per dispositivi mobili.
- Metodologie di Lavoro: Le metodologie di sviluppo sono essenziali per il successo del progetto. Verifica se l’azienda utilizza metodologie agili o altre approcci che consentono di adattarsi alle esigenze mutevoli e di mantenere una comunicazione continua con il cliente durante tutto il processo.
- Supporto e Manutenzione: Lo sviluppo del software non si conclude con il lancio iniziale. Il supporto e la manutenzione continuativa sono cruciali per garantire il corretto funzionamento dell’applicazione nel tempo. Assicurati che l’azienda sia disposta e in grado di fornire assistenza post-lancio.
- Trasparenza e Comunicazione: Una comunicazione chiara e aperta è essenziale durante il processo di sviluppo. Cerca un’azienda che ti tenga aggiornato sullo stato del progetto, risponda prontamente alle tue domande e sia disposta a discutere le tue idee e suggerimenti.
- Reputazione e Recensioni: Fai una ricerca sulla reputazione dell’azienda. Leggi recensioni online, chiedi referenze e parla con clienti precedenti se possibile. Questo ti fornirà un’idea più precisa dell’esperienza che puoi aspettarti.
- Budget e Scalabilità: Considera il budget che hai a disposizione e discuti con l’azienda le opzioni di prezzo e i piani di pagamento. Inoltre, verifica se l’azienda ha la capacità di scalare il progetto in caso di espansione futura.
In conclusione, la scelta dell’azienda giusta per lo sviluppo software è un passo critico che richiede tempo e attenzione. Analizza attentamente le competenze, l’esperienza, le metodologie di lavoro e la reputazione dell’azienda prima di prendere una decisione. Una collaborazione solida con un team di sviluppatori competenti può portare a un software personalizzato di alta qualità che soddisfi pienamente le tue esigenze aziendali.
Affidati solo a Software House esperte in progettazione e sviluppo software
Affidati ad Oimmei Digital Consulting per lo sviluppo software e applicazioni, abbiamo base in Toscana ma lavoriamo quotidianamente con aziende in tutto il mondo.
Oimmei Digital Consulting
info@oimmei.com
Livorno, Italy
(Foto copertina di Radowan Nakif Rehan su Unsplash)
The post Sviluppo software di successo e benefici per la tua azienda first appeared on Oimmei Digital Consulting.
]]>The post Parse di oggetti tipati con Yup cast first appeared on Oimmei Digital Consulting.
]]>C’è una grande quantità e varietà di fonti dati: API web, SDK, documenti sul file system, il localStorage del browser, una query string. Spesso, ad esempio, può capitare di dover reperire dati serializzati in forma testuale che magari noi stessi avevamo salvato da qualche parte per memorizzare una scelta dell’utente.
Leggere queste informazioni, che lo si faccia manualmente con gli strumenti nativi di JavaScript o che si usi una libreria, tipicamente è piuttosto semplice: si interroga la fonte dati, si ottiene un elemento o una lista ed è tutto pronto.
…oppure no?
JavaScript, si sa, è un linguaggio dinamicamente tipato, e usare TypeScript – come facciamo noi – per aiutarci a identificare errori di tipo prima che sia troppo tardi non toglie il fatto che a runtime la tipizzazione di variabili e proprietà sia dinamica. Questo significa che, soprattutto quando si leggono dati da fonti puramente testuali, potremmo ottenere valori che non ci aspettiamo.
Tipicamente ciò avviene con campi numerici, ma può riguardare qualunque altro tipo di dato non testuale: abbiamo un valore numerico salvato da qualche parte, lo recuperiamo da una fonte dati e lo usiamo in un confronto o in qualche altra operazione aspettandoci che sia un number, per poi scoprire a runtime che in realtà si tratta di una stringa, ritrovandoci con bug subdoli e poco evidenti a prima vista. Vediamo un esempio pratico.
Immaginiamo una situazione che sarà sicuramente capitata a chiunque si trovi nello sviluppo web: stiamo creando un’applicazione React che salva in query string i dati di una deliziosa pizza, e in seguito li recupera per mostrarli all’utente.
Creiamo allora un nuovo progetto create-react-app, con TypeScript come piace a noi, e mettiamoci al lavoro.
npx create-react-app react18-typed-parsing --template typescript
Per serializzare e deserializzare gli oggetti useremo la libreria Qs, con react-router e react-router-dom per la manipolazione della query string, senza dimenticare le dichiarazioni TypeScript.
npm install qs react-router react-router-dom npm install -D @types/qs
Innanzitutto, creiamo un semplice modello dati per la nostra pizza, con un ID e un paio di campi testuali.
// src/models/Pizza.ts
// Interfaccia per la struttura dati pizza.
export interface Pizza {
id: number
name: string
description?: string
}
La nostra applicazione web avrà due componenti.
- PizzaWriter prenderà una Pizza e la salverà nella query string.
- PizzaReader starà in ascolto sulla query string e, un po’ come me quando aspetto il fattorino di Just Eat sulla porta, non appena ci troverà una Pizza la consumerà e ne mostrerà i dati all’utente.
I componenti si troveranno all’interno del contenitore PizzaWrapper…
// src/pages/PizzaWrapper.tsx
import React, {ReactElement} from 'react';
import PizzaWriter from '../components/PizzaWriter';
import PizzaReader from '../components/PizzaReader';
const PizzaWrapper = (): ReactElement | null => {
return (
<>
<PizzaWriter/>
<PizzaReader/>
</>
);
}
export default PizzaWrapper;
…che sarà la root della navigazione.
// src/App.tsx
import React from 'react';
import {
createBrowserRouter,
RouterProvider,
} from "react-router-dom";
import './App.css';
import PizzaWrapper from './pages/PizzaWrapper';
const router = createBrowserRouter([
{
path: '/',
element: <PizzaWrapper/>,
},
]);
function App() {
return (
<RouterProvider router={router}/>
);
}
export default App;
PizzaWriter è semplice: alla pressione di un pulsante, serializza un oggetto pizza con Qs e salva il risultato in query string con l’hook di react-router-dom useSearchParams.
// src/components/PizzaWriter.tsx
import React, {ReactElement} from 'react';
import {useSearchParams} from 'react-router-dom';
import Qs from 'qs';
import {Pizza} from '../models/Pizza';
// La nostra pizza, da salvare in query string.
const pizzaToWrite: Pizza = {
id: 1,
name: 'Margherita',
description: 'La classica!',
};
const PizzaWriter = (): ReactElement => {
// Metodo per modificare la query string.
const [, setSearchParams] = useSearchParams();
// Al click, la pizza viene salvata in query string.
const savePizzaInQueryString = (): void => {
setSearchParams(Qs.stringify(pizzaToWrite));
}
return (
<div className={'querystring-writer'}>
<h1>Query string writer</h1>
<button onClick={savePizzaInQueryString}>
Salva pizza in query string
</button>
</div>
);
}
export default PizzaWriter;
PizzaReader è dove le cose iniziano a complicarsi un po’. Di base, quel che vogliamo è stare in ascolto sulla query string, sempre con useSearchParams, per essere pronti a ricevere una Pizza e metterla nello stato. Appena arriva, mostriamo all’utente i dati della Pizza. Ci aspettiamo di ricevere una margherita, quindi controlliamo anche, in base all’ID, che la pizza sia quella che abbiamo ordinato.
Ma come facciamo a essere sicuri che l’oggetto che leggiamo sia proprio una Pizza?
// src/components/PizzaReader.tsx
import React, {ReactElement, useEffect, useState} from 'react';
import {useSearchParams} from 'react-router-dom';
import Qs from 'qs';
import {Pizza} from '../models/Pizza';
// La pizza che ci si aspetta di ricevere dalla query string.
const pizzaToRead = {
id: 1,
name: 'Margherita',
description: 'La classica!',
};
const PizzaReader = (): ReactElement | null => {
const [searchParams] = useSearchParams();
// La pizza che è stata recuperata dalla query string.
const [pizza, setPizza] =
useState<Pizza | null>(null);
useEffect(() => {
// Parsing della pizza dalla query string.
const pizzaRaw = Qs.parse(searchParams.toString());
// TODO: e adesso?
}, [searchParams]);
// I dati della pizza vengono mostrati all'utente, se presenti.
return (
<div className={'querystring-reader'}>
<h1>Query string reader</h1>
{pizza !== null ? (
<div className={'pizza-info'}>
<div>
<div className={'bold'}>ID</div>
<div>{pizza.id}</div>
</div>
<div>
<div className={'bold'}>Nome</div>
<div>{pizza.name}</div>
</div>
<div>
<div className={'bold'}>Descrizione</div>
<div>{pizza.description}</div>
</div>
<div>
{/* Se la pizza è una margherita, si mostra l'informazione, in base all'ID. */}
<div className={'bold'}>Margherita</div>
<div>{pizza.id === pizzaToRead.id ? 'Sì' : 'No'}</div>
</div>
</div>
) : (
'Nessuna pizza in query string :('
)}
</div>
);
};
export default PizzaReader;
Una strada potrebbe essere quella di definire una type guard, per assicurarci che l’oggetto in query string abbia i campi che ci aspettiamo.
// src/helpers/pizzaHelper.ts
import {Pizza} from '../models/Pizza';
// Type guard per verificare che un oggetto qualsiasi sia una pizza.
export const isPizza = (obj: any): obj is Pizza => {
return 'id' in obj && 'name' in obj && 'description' in obj;
}
Proviamo a completare la useEffect di PizzaReader così.
import {isPizza} from '../helpers/pizzaHelper';
…
useEffect(() => {
// Parsing della pizza dalla query string.
const pizzaRaw = Qs.parse(searchParams.toString());
// Se l'oggetto è una pizza, lo si salva nello stato.
if (isPizza(pizzaRaw)) {
setPizza(pizzaRaw);
}
}, [searchParams]);
Dal punto di vista di TypeScript, è tutto a posto. Facciamo partire la nostra applicazione con…
npm run start
…e apriamo il browser, per vedere PizzaReader pronto a ricevere una Pizza.

Premiamo senza indugio il pulsante per consegnare il nostro stupendo pacchetto di amore e carboidrati, e vediamo come cambia la situazione.
A una prima occhiata è tutto a posto, ma qualcosa non va. I dati della Pizza sembrano corretti, se non per il fatto che PizzaReader non vede la Pizza come una margherita. Come mai?

La chiave è nel confronto che stiamo facendo sull’ID.
<div>
{/* Se la pizza è una margherita, si mostra l'informazione, in base all'ID. */}
<div className={'bold'}>Margherita</div>
<div>{pizza.id === pizzaToRead.id ? 'Sì' : 'No'}</div>
</div>
Il problema è che la pizzaToRead è stata definita nel nostro codice, rispettando l’interfaccia definita, mentre pizza viene recuperata dalla query string. Nel primo caso, l’ID viene correttamente impostato come un number; nel secondo, però, non avendo la query string nessuna indicazione sul tipo delle variabili, tutti i valori avranno tipo string a runtime. La strict equality che ci aspettiamo, dunque, non è rispettata: i tipi sono diversi, anche se TypeScript non può saperlo.
Risolvere questa situazione non è banale come può sembrare. Certo, per un caso così semplice potremmo usare la semplice equality, ma in situazioni più complesse? Se dovessimo usare un metodo specifico di String o di Number?
Si potrebbe pensare di rendere più stretta la type guard isPizza per controllare anche il tipo dei valori, ma questo ci porterebbe a non considerare l’oggetto in query string come una Pizza, lasciando il PizzaReader a stato e pancia vuoti. E allora? Dobbiamo costruire una complessa funzione parser per ogni interfaccia della nostra applicazione?
No: esiste un modo più semplice e sicuro, e viene dalla libreria Yup.
Se siete abituati a lavorare in React, molto probabilmente conoscerete già Yup: è una delle librerie più diffuse per la validazione dei form, spesso usata insieme a Formik. Ma validare i form non è l’unica cosa di cui è capace; per il nostro problema, in particolare, ci interessa il metodo cast. Si tratta di una funzionalità che permette, dato un valore che può essere un oggetto, di tentare di estrapolare un secondo valore che rispetta uno specifico schema, proprio come quelli usati nella validazione dei form.
Installiamo Yup e le sue dichiarazioni di tipo…
npm install yup npm install -D @types/yup
…e, insieme all’interfaccia, creiamo anche lo schema Yup per Pizza.
// src/models/Pizza.ts
import * as yup from 'yup';
// Interfaccia per la struttura dati pizza.
export interface Pizza {
id: number
name: string
description?: string
}
// Schema Yup per la struttura dati pizza.
export const pizzaSchema = yup.object({
id: yup.number().required(),
name: yup.string().required(),
description: yup.string(),
});
Infine, creiamo un terzo componente, PizzaTypedReader. La sua struttura sarà identica al PizzaReader, se non per il fatto che userà lo schema per il parsing del valore in query string.
// src/components/PizzaTypedReader.tsx
import React, {ReactElement, useEffect, useState} from 'react';
import {useSearchParams} from 'react-router-dom';
import Qs from 'qs';
import {Pizza, pizzaSchema} from '../models/Pizza';
// La pizza che ci si aspetta di ricevere dalla query string.
const pizzaToRead = {
id: 1,
name: 'Margherita',
description: 'La classica!',
};
const PizzaTypedReader = (): ReactElement | null => {
…
useEffect(() => {
// Parsing della pizza dalla query string.
const pizzaRaw = Qs.parse(searchParams.toString());
// Si usa Schema.cast di Yup per tentare di fare il parsing dell'oggetto.
try {
// Richiesta la type assertion as Pizza per evitare errori di tipo.
const newPizza = pizzaSchema.cast(pizzaRaw) as Pizza;
// L'oggetto è una pizza.
setPizza(newPizza);
} catch (error) {
// L'oggetto non è una pizza.
setPizza(null);
}
}, [searchParams]);
…
};
export default PizzaTypedReader;
Il metodo cast dello schema tenterà di restituire un oggetto che rispetta la struttura dati definita. In questo caso, il valore string ‘1’ subirà un casting nel number 1, dato che lo schema impone che il campo id sia di tipo number. Se l’input non è compatibile con lo schema, ad esempio perché id è una stringa non numerica oppure perché manca un campo non opzionale, verrà lanciato un errore. Nel momento in cui la chiamata ha successo, quindi, possiamo essere certi che newPizza sia una Pizza, con una piccola type assertion per convincere anche TypeScript della cosa.
Aggiungiamo il terzo componente insieme agli altri…
// src/pages/PizzaWrapper.tsx
import React, {ReactElement} from 'react';
import PizzaWriter from '../components/PizzaWriter';
import PizzaReader from '../components/PizzaReader';
import PizzaTypedReader from '../components/PizzaTypedReader';
const PizzaWrapper = (): ReactElement | null => {
return (
<>
<PizzaWriter/>
<PizzaReader/>
<PizzaTypedReader/>
</>
);
}
export default PizzaWrapper;
…e proviamo di nuovo.
Adesso sì che ci siamo! Grazie a Yup, l’ID di newPizza è un number, e la strict comparison ha successo.

Possiamo usare il metodo cast in qualunque situazione per assicurarci che i tipi a runtime siano quelli che ci aspettiamo nel codice: valori scalari, oggetti, array di oggetti, con ogni tipo di schema, non importa quanto complesso. Questo ci permette anche di validare la struttura di dati provenienti da fonti poco affidabili, ad esempio informazioni che possono essere facilmente modificate da utenti malintenzionati, come il localStorage del browser o, appunto, una query string. Occhio a non farci troppo affidamento, però: questa validazione si limita al tipo, il contenuto effettivo è tutta un’altra storia!Spero che questa lettura possa essere stata utile. Se vi va, potete dare un’occhiata alla repository del progetto. Io credo che ordinerò una pizza.
Foto di Lukas
The post Parse di oggetti tipati con Yup cast first appeared on Oimmei Digital Consulting.
]]>The post iOS – iPhone Operating System first appeared on Oimmei Digital Consulting.
]]>iOS è noto per la sua interfaccia intuitiva e pulita, che permette agli utenti di navigare tra le app e le funzionalità in modo semplice e fluido. Oltre alla sua facilità d’uso, iOS offre un ecosistema coeso in cui le applicazioni e i servizi si integrano senza sforzo tra di loro. Questa integrazione consente agli utenti di sincronizzare facilmente dati, foto, video e altro ancora attraverso i loro dispositivi Apple.
Un altro punto forte di iOS è la sua attenzione alla sicurezza. Apple è rinomata per le misure di protezione dei dati degli utenti e della loro privacy, attraverso l’utilizzo del riconoscimento facciale avanzato (Face ID) e del sistema di autenticazione biometrica (Touch ID). Queste tecnologie garantiscono che solo il proprietario del dispositivo possa accedervi, aumentando la sicurezza delle informazioni personali.
Inoltre, iOS è noto per il suo App Store, una piattaforma che ospita milioni di applicazioni sviluppate da terze parti. Gli sviluppatori di app possono creare software innovativo e creativo, ampliando le funzionalità dei dispositivi Apple e offrendo agli utenti un’ampia varietà di scelte.
Nel complesso, l’acronimo iOS rappresenta molto più di un semplice sistema operativo. È un’interfaccia che connette gli utenti ai loro dispositivi, semplificando la vita digitale e offrendo una gamma di servizi, funzionalità e sicurezza ineguagliati. La costante evoluzione di iOS dimostra l’impegno di Apple nell’offrire esperienze d’uso all’avanguardia, mantenendo al contempo l’integrità dei dati personali degli utenti.
Foto di Szabo Viktor su Unsplash
The post iOS – iPhone Operating System first appeared on Oimmei Digital Consulting.
]]>The post Come creare un’App di successo first appeared on Oimmei Digital Consulting.
]]>La competenza tecnica, l’impegno e la creatività sono elementi fondamentali per sviluppare un’App mobile di successo. Anche se inizialmente potrebbe sembrare un processo relativamente semplice, la realtà è che creare un’app richiede una pianificazione attenta e una strategia mirata. Prima di iniziare a sviluppare un’app aziendale, è essenziale valutare attentamente gli obiettivi aziendali, il pubblico di riferimento e le opportunità offerte dai canali mobile, assicurandosi che sviluppare un’App sia una scelta strategica.
Quali sono i vantaggi di avere un’App aziendale?
- Maggiore visibilità e presenza: sviluppare un’App mobile aziendale consente di essere facilmente accessibile agli utenti 24 ore su 24, 7 giorni su 7. Essendo presente direttamente sullo smartphone degli utenti, l’app offre una visibilità costante e permette di raggiungere un pubblico più ampio.
- Migliore esperienza utente: le app offrono un’interfaccia e un’esperienza utente ottimizzate per i dispositivi mobili. I clienti possono accedere in modo rapido e intuitivo alle informazioni, ai servizi o ai prodotti dell’azienda, migliorando la fruibilità e l’interazione con il brand.
- Fidelizzazione dei clienti: attraverso lo sviluppo di un’app, è possibile offrire funzionalità personalizzate e vantaggi esclusivi ai clienti fedeli. Ad esempio, programmi di fedeltà, sconti o promozioni speciali riservate agli utenti dell’app. Ciò favorisce l’engagement e la fidelizzazione della clientela.
- Comunicazione diretta: un’app consente di comunicare direttamente con gli utenti tramite notifiche push. Questo mezzo di comunicazione immediato consente di inviare informazioni importanti, aggiornamenti, offerte speciali o notizie rilevanti, mantenendo un contatto diretto e costante con i clienti.
- Maggiori opportunità di vendita: con l’uso di un’app, è possibile integrare un sistema di e-commerce o di prenotazione dei servizi dell’azienda. Ciò consente agli utenti di effettuare acquisti o prenotazioni direttamente dall’app, migliorando l’accessibilità e facilitando le transazioni.
- Differenziazione dalla concorrenza: sviluppare una applicazione mobile dedicata può conferire all’azienda un vantaggio competitivo rispetto ai concorrenti che non offrono un’esperienza mobile dedicata. Creare un’applicazione di qualità e ben progettata può distinguere l’azienda e migliorare la brand awareness.
Come creare un’applicazione mobile?
Progettare e sviluppare un’App mobile, richiede creatività, innovazione e competenza tecnica, soprattutto se si desidera un prodotto personalizzato in base alle proprie necessità e obiettivi di marketing. Lo sviluppatore deve avere la capacità e l’esperienza tecnica necessaria per comprendere le esigenze del mercato, sviluppare un’interfaccia accattivante e garantire un’esperienza utente ottimale. Anche se questo percorso può risultare più complesso e lungo, il risultato sarà la creazione di un’applicazione completamente personalizzata e sviluppata ad hoc per soddisfare le esigenze del cliente.
Le fasi per sviluppare un’App mobile:
- Raccolta delle informazioni: raccogliere informazioni dal mercato è fondamentale per creare e progettare un’applicazione digitale. È importante ascoltare il cliente e comprendere le sue necessità e i suoi desideri, valutando se ciò rappresenta un’opportunità. Un’idea deve essere supportata dalla volontà di risolvere un problema, soddisfare una richiesta o rispondere a un bisogno.
- UI: in questa fase si progetta l’applicazione. Lo sviluppatore deve immaginare le schermate, le funzioni da includere e la loro posizione. Dopodiché, si passa alla creazione di wireframe digitali, fino a definire un’interfaccia che dia forma alle idee. Si procede con la progettazione della grafica e l’interfaccia viene corretta e modificata fino a raggiungere la versione finale, rispettando le richieste iniziali del cliente.
- Sviluppo: lo sviluppo deve essere accompagnato da test che non devono essere né troppo precoci né troppo tardivi. Le aspettative degli utenti non devono essere deluse in questa fase. Basandosi sulla UX, è possibile apportare correzioni e modifiche minori all’interfaccia utente.
- Bug-Fixing: questa fase si riferisce al periodo di prova dell’applicazione. È necessario testare l’applicazione in diversi contesti, con vari dispositivi, e apportare le correzioni necessarie. I bug devono essere risolti e l’interfaccia, se necessario, deve essere migliorata, tenendo conto delle eventuali richieste ulteriori del cliente dopo la fase di testing.
- Approvazione: una volta che il cliente ha approvato la nuova applicazione, è necessario caricarla sui relativi store, in attesa di approvazione da parte delle piattaforme di distribuzione.
Come creare un’App mobile iOS
Sviluppare un’App Mobile per iOS coinvolge diverse fasi, tra cui la pianificazione, la progettazione, lo sviluppo, il test e il rilascio dell’app.
Pianificazione: In questa fase è importante definire l’obiettivo dell’app, identificare il target, fare una ricerca di mercato per comprendere le esigenze degli utenti e creare un piano di sviluppo dettagliato.
Progettazione: La progettazione dell’interfaccia utente è un aspetto cruciale nello sviluppo di un’app iOS. Utilizzando il framework UIKit o SwiftUI, è possibile creare un’interfaccia utente intuitiva e coinvolgente. È necessario assicurarsi che il design segua le linee guida di progettazione di Apple per offrire un’esperienza utente coerente con l’ecosistema iOS.
Sviluppo: Durante questa fase, il design dell’interfaccia viene tradotto in codice. Utilizzando il linguaggio di programmazione Swift o Objective-C e l’ambiente di sviluppo integrato (IDE) Xcode, si sviluppano le funzionalità dell’app, come la gestione dei dati, l’integrazione con servizi esterni e la logica di business.
Test: Il testing è un processo critico per garantire il corretto funzionamento dell’app e offrire un’esperienza utente fluida. Utilizzando strumenti di testing forniti da Apple come XCTest, è possibile eseguire test approfonditi per identificare bug, problemi di prestazioni o altre imperfezioni.
Rilascio: Una volta che l’app è stata testata con successo, è giunto il momento del rilascio. Il primo passo è quello di registrarsi come sviluppatore Apple sul portale Apple Developer Program, creare un certificato di distribuzione, generare un profilo di provisioning e inviare l’app per la revisione attraverso l’App Store Connect. Apple eseguirà una revisione per verificare che l’applicazione soddisfi le linee guida dell’App Store prima di renderla disponibile agli utenti.
È importante considerare anche il supporto continuo dell’applicazione dopo il rilascio. Per questo motivo, è fondamentale mantenere un’app aggiornata con nuove funzionalità, correzioni di bug e adattamenti alle nuove versioni di iOS.
Come creare un’App mobile Huawei
Per sviluppare un’App mobile Huawei, è possibile utilizzare l’IDE (Integrated Development Environment) ufficiale di Huawei chiamato Huawei DevEco Studio. Questo ambiente di sviluppo fornisce gli strumenti e le risorse necessarie per creare un’app personalizzata per i dispositivi Huawei.
Huawei DevEco Studio offre un editor visuale intuitivo che consente di creare e personalizzare le schermate dell’app. Trascina e rilascia i componenti UI desiderati, come pulsanti, caselle di testo ed elenchi, per creare un’interfaccia accattivante e funzionale.
L’IDE di Huawei supporta diversi linguaggi di programmazione, ma i più comuni sono Java e Kotlin per lo sviluppo di app Android. Utilizzando uno di questi linguaggi, è possibile aggiungere funzionalità all’app, come l’accesso ai dati, l’interazione con i servizi web e la gestione dei dati.
Una volta completato i test e lo sviluppo dell’app, si può procedere alla compilazione del progetto che permetterà di generare un pacchetto di distribuzione, come un file APK (Android Package) o un file HAP (Huawei Application Package), a seconda delle esigenze specifiche. Infine, si passa alla distribuzione dell’app nella Huawei AppGallery o in altre piattaforme di distribuzione Huawei.
Come creare un’App mobile Android
La progettazione dell’interfaccia utente riveste un ruolo cruciale all’interno del processo di sviluppo di un’applicazione mobile Android. Esistono due approcci principali: il primo implica l’utilizzo del linguaggio XML in combinazione con librerie di supporto come Material Design, mentre il secondo abbraccia le nuove metodologie introdotte da Jetpack Compose. Quest’ultimo approccio ha radicalmente ridefinito il processo, eliminando completamente l’impiego dell’XML per l’implementazione dei componenti dell’interfaccia.
Jetpack Compose introduce una serie di vantaggi che permettono di superare le limitazioni del tradizionale toolkit Android:
- Flessibilità nell’adattamento: Con Jetpack Compose, si è liberati dai vincoli del sistema operativo. Questa flessibilità facilita l’apportare regolazioni e correzioni di bug, preservando al contempo la retrocompatibilità dell’applicazione.
- Componenti manutenibili: Il framework consente lo sviluppo mediante l’utilizzo di componenti più gestibili e semplificati. Ciò si traduce in un processo di manutenzione più agevole e in una curva di apprendimento meno ripida per i nuovi sviluppatori.
- Gestione efficiente dei contesti: Jetpack Compose semplifica l’organizzazione dei contesti, eliminando la necessità di apportare modifiche su più file al fine di rendere funzionante l’interfaccia utente. Questo snellisce il flusso di lavoro e favorisce la coerenza.
- Gestione dello stato semplificata: Il framework agevola notevolmente la gestione dello stato dell’applicazione. Questo aspetto critico diventa più comprensibile e gestibile attraverso gli strumenti messi a disposizione da Jetpack Compose.
Un altro elemento fondamentale è l’usabilità dell’app. L’interfaccia utente deve essere intuitiva, consentendo agli utenti di navigare facilmente tra le diverse schermate. L’aspetto visivo, come l’utilizzo dei colori, delle icone e della tipografia, è altrettanto importante per creare un’esperienza coinvolgente per gli utenti.
Successivamente, durante la fase di sviluppo, il design dell’interfaccia utente viene tradotto in codice. Utilizzando il linguaggio di programmazione Java o Kotlin insieme all’ambiente di sviluppo Android Studio, è possibile implementare le funzionalità dell’app, tra cui la gestione dei dati, l’integrazione con servizi esterni e la logica di business.
Sebbene Java sia stato il linguaggio di programmazione principale per sviluppare un’ App mobile per Android, Kotlin sta diventando sempre più popolare grazie alla sua sintassi più concisa e moderna. Entrambi i linguaggi offrono funzionalità potenti per lo sviluppo di app Android.
Android Studio rappresenta l’IDE (Integrated Development Environment) ufficiale per lo sviluppo di app Android. Esso fornisce strumenti di sviluppo avanzati, tra cui un editor di codice, un debugger e un emulatore per testare l’app su diversi dispositivi virtuali.
Durante il processo per sviluppare un’App mobile Android, è importante seguire i principi di sviluppo di Android, come l’adozione delle migliori pratiche di programmazione, la modularità del codice e l’ottimizzazione delle prestazioni. È fondamentale gestire correttamente i dati dell’app, utilizzare le API fornite dai servizi esterni e implementare la logica di business in modo robusto.
App Store Optimization (ASO)
L’App Store Optimization (ASO) è un processo finalizzato a ottimizzare nel tempo un’applicazione mobile e il suo funzionamento, al fine di posizionarla tra i primi risultati di ricerca nei vari App Store. Quando un utente digita una query di ricerca nel campo apposito su Google Play o dall’App Store, vengono mostrati risultati che costituiscono un elenco di applicazioni. Più il creatore dell’applicazione attua una strategia ASO efficace, più l’applicazione stessa sarà posizionata nelle prime posizioni della lista.
L’ASO implica lo sviluppo dell’applicazione seguendo i criteri appropriati per garantire la massima visibilità, distinguendosi dalle altre e posizionandosi in alto nello store di riferimento. Il risultato di questo processo è una maggiore probabilità che gli utenti visitino la pagina dell’app e procedano con il download.
Esistono diversi strumenti per eseguire l’ASO e promuovere un’App, ad esempio, gli elementi “On Page” e “Off Page”.
Gli elementi “On Page” riguardano direttamente la creazione e lo sviluppo dell’applicazione, mentre quelli “Off Page” influenzano la promozione dell’app senza intervenire direttamente su di essa, migliorando l’indicizzazione e il posizionamento nei risultati di ricerca.
Una strategia di ASO efficace comprende l’ottimizzazione del titolo dell’app, delle parole chiave, della descrizione, delle immagini e delle recensioni. Anche la promozione tramite i canali di marketing, pubblicità mirata e coinvolgimento degli utenti può contribuire a migliorare la visibilità e l’indicizzazione delle App negli Store.
Gli strumenti “On Page” (h3)
Gli strumenti On Page per l’ASO comprendono diversi elementi che contribuiscono a ottimizzare la visibilità e il posizionamento di un’App negli Store. Utilizzare questi strumenti in modo efficace consente di ottimizzare la visibilità dell’app, migliorare il posizionamento nei risultati di ricerca e attrarre utenti interessati. Una combinazione di titolo esplicativo, l’uso di parole chiave pertinenti, una descrizione accattivante, un Visual Branding coinvolgente e la corretta categorizzazione dell’App, porterà a risultati di ASO positivi.
Vediamo questi elementi uno ad uno:
- Titolo: Il titolo dell’applicazione è il suo nome e deve essere esplicativo. È consigliabile mantenere il titolo entro i 50 caratteri per evitare che venga tagliato nei risultati di ricerca. Inoltre, è importante includere la parola chiave principale nel titolo per migliorare la sua rilevanza e indicizzazione.
- Parole chiave: Le parole chiave sono cruciali per identificare l’applicazione e corrispondere alle ricerche degli utenti. È importante selezionare parole chiave pertinenti e popolari che riflettano le caratteristiche principali dell’App. Queste parole chiave possono essere utilizzate nella descrizione, nelle recensioni e in altre sezioni pertinenti dell’App Store.
- Descrizione: la descrizione è un elemento fondamentale per suscitare l’interesse degli utenti. Deve essere scritta in modo accattivante e orientato al marketing, evidenziando le nuove funzionalità dell’app in 170 caratteri. La descrizione dovrebbe fornire una panoramica chiara delle caratteristiche e dei benefici dell’app, stimolando la curiosità dell’utente e incoraggiandolo al download.
- Engagement: questa sezione offre una descrizione più completa dell’applicazione, spiegando la sua tipologia, le funzionalità e le possibilità che offre agli utenti. Pur non influenzando direttamente l’indicizzazione, il fattore Engagement ha un impatto significativo sui potenziali utenti, completando le informazioni fornite nella descrizione e fornendo una visione più dettagliata dell’applicazione.
- Visual Branding: il Visual Branding comprende tutti gli elementi visibili che contribuiscono a formare un’idea dell’applicazione. Questi includono l’icona, gli screenshot e, eventualmente, un video. L’icona è l’immagine che appare sullo schermo del dispositivo mobile e deve essere riconoscibile e rappresentativa dell’app. Gli screenshot forniscono una visione statica delle schermate principali dell’app, mentre il video aiuta a comprendere meglio il funzionamento, la grafica e le animazioni presenti nell’applicazione. Un video ben realizzato può valorizzare l’app e promuoverla in modo efficace.
- Categoria: la scelta della categoria appropriata per un’applicazione è fondamentale. Assegnare un’app a una categoria sbagliata può ridurre la sua visibilità e compromettere la credibilità dello sviluppatore. È importante selezionare attentamente la categoria più pertinente che corrisponda alle aspettative degli utenti e alle ricerche all’interno degli store.
Gli Strumenti “Off Page”
Gli strumenti Off Page si riferiscono alle attività di promozione che possono influenzare l’ASO di un’applicazione senza intervenire direttamente sull’app stessa. Questi strumenti mirano a migliorare l’indicizzazione, l’autorità e la visibilità dell’App al di fuori dello Store. È importante considerare una combinazione di strategie On Page e Off Page per ottenere i migliori risultati nell’ASO e promuovere l’applicazione in modo efficace.
Questi sono alcuni degli strumenti Off Page ASO più comuni:
- Link building: Ottenere link da fonti autorevoli e pertinenti può migliorare la visibilità dell’app e aumentare il suo ranking nei motori di ricerca. Questo può essere fatto attraverso la creazione di collegamenti da siti web di rilievo, blog, directory, recensioni e menzioni sui social media.
- Recensioni e valutazioni: Ottenere recensioni positive e valutazioni elevate da parte degli utenti può influenzare positivamente la credibilità e l’affidabilità dell’app. Le recensioni esterne, come quelle pubblicate su siti di recensioni di app o blog specializzati, possono anche aumentare la visibilità dell’applicazione.
- Marketing influencer: Collaborare con influencer o esperti del settore può aumentare l’esposizione e la consapevolezza dell’applicazione. Gli influencer possono promuovere l’app attraverso recensioni, articoli, video o post sui social media, raggiungendo così un pubblico più ampio e generando interesse.
- Presenza sui social media: Utilizzare i social media per promuovere l’app, creare una community di utenti e interagire con il pubblico può contribuire alla sua visibilità e popolarità. Condividere contenuti correlati all’app, rispondere alle domande degli utenti e incoraggiare il coinvolgimento degli utenti può generare interesse e aumentare il download dell’applicazione.
- Relazioni con i media: Collaborare con i media o gli editori per ottenere copertura mediatica può aumentare la visibilità e l’autorità dell’app. Questo può includere comunicati stampa, interviste, articoli o partecipazione a eventi del settore.
- Ottimizzazione del web: L’ottimizzazione del sito web dell’app o la creazione di una pagina dedicata all’App possono contribuire alla sua visibilità nei motori di ricerca. Questo può includere l’uso di parole chiave pertinenti, meta tag appropriate, descrizioni coinvolgenti e link interni o esterni pertinenti.
L’App Store Optimization è un processo continuo che richiede un monitoraggio costante delle prestazioni dell’App, l’aggiornamento dei metadati, l’adeguamento alle tendenze di ricerca e l’ottimizzazione in base ai feedback degli utenti. Implementando una strategia solida, è possibile aumentare la visibilità dell’app, migliorare il posizionamento nei risultati di ricerca e massimizzare il numero di download e di interazioni con l’applicazione.
Advertising per le App Android
Per ottenere maggiori visibilità e un numero crescenti di installazioni di un’App Android, la strategia migliore da adottare è l’Advertising di Google. Questo approccio coinvolge principalmente la promozione dell’app attraverso annunci pubblicitari a pagamento all’interno del Google Play Store, utilizzando le potenti “App Campaigns” disponibili sulla piattaforma di advertising di Google, nota come Google Ads.
Per iniziare il processo, è importante seguire queste fasi chiave:
- Reazione della campagna: Il primo passo consiste nella creazione di una campagna pubblicitaria tramite Google Ads. È possibile impostare un budget giornaliero e l’offerta per clic (CPC) che si è disposti a pagare per ogni click sull’annuncio.
- Scelta delle parole chiave: La selezione delle parole chiave giuste è fondamentale per far sì che gli annunci vengano mostrati agli utenti interessati. Scegliere parole chiave pertinenti e rilevanti per l’app e il suo contenuto, in modo da aumentare la probabilità che l’annuncio raggiunga il pubblico giusto.
- Creazione dell’annuncio: La creatività pubblicitaria deve essere coinvolgente e persuasiva. Include un titolo accattivante, un breve testo descrittivo e un’immagine o un video dell’applicazione. Questi elementi sono essenziali per catturare l’attenzione degli utenti e spingerli a fare clic sull’annuncio.
- Targeting dell’audience: Specificare il pubblico a cui si desidera mostrare l’annuncio, utilizzando opzioni di targeting come il paese, la lingua, l’età, il genere e gli interessi degli utenti. Questo aiuterà a raggiungere le persone giuste e aumentare la rilevanza della tua campagna.
- Pubblicazione dell’annuncio: Una volta configurata la campagna e creato l’annuncio, è possibile pubblicarlo sul Google Play Store. L’ annuncio verrà mostrato agli utenti interessati alle parole chiave selezionate e al pubblico di destinazione che hai scelto.
- Monitoraggio delle prestazioni: È essenziale tenere sotto controllo le prestazioni della campagna pubblicitaria e monitorare attentamente il numero di impressioni (quante volte l’annuncio è stato mostrato), il tasso di clic (quante volte è stato cliccato) e altre metriche chiave per valutare l’efficacia dell’annuncio ed eventualmente apportare miglioramenti e cambiamenti.
L’obiettivo principale è quello di aumentare il numero di installazioni dell’app, migliorando il suo posizionamento e la visibilità organica all’interno del Google Play Store. Le installazioni influenzano positivamente l’algoritmo del Play Store, facendo sì che l’app venga suggerita più spesso agli utenti durante le loro ricerche di app simili.
È importante sottolineare che l’ASO non riguarda solo la promozione a pagamento. La cura di altri aspetti, come il titolo, la descrizione, le immagini e le recensioni degli utenti, gioca un ruolo fondamentale nella visibilità organica dell’app. Una combinazione efficace di un’ottimizzazione ASO accurata e una campagna di advertising mirata può aumentare notevolmente le possibilità di successo dell’app sul Google Play Store.
Apple Search Ads Advanced
Apple Search Ads Advanced è una piattaforma pubblicitaria fornita da Apple per promuovere le app all’interno dell’App Store. È progettato per aiutare gli sviluppatori a migliorare la visibilità delle loro app e ad aumentare il numero di download.
Ecco alcuni punti chiave da considerare su Apple Search Ads Advanced:
- Ricerca e targeting delle parole chiave: Con Apple Search Ads Advanced, è possibile selezionare le parole chiave pertinenti per le quali si desidera che la App venga mostrata come risultato di ricerca. Questo consente di raggiungere un pubblico specifico che sta cercando app simili alla tua.
- Tipi di campagna: Apple Search Ads Advanced offre due tipi di campagne: “Ricerca” e “Scopri”. Le campagne di ricerca vengono visualizzate come risultati di ricerca nella pagina degli elenchi dell’App Store. Le campagne “Scopri” vengono visualizzate nella sezione “Oggi” o “Scopri” dell’App Store. È possibile scegliere il tipo di campagna in base agli obiettivi di promozione della app.
- Segmentazione demografica e geografica: Specificare l’ audience di destinazione in base a fattori demografici come età, genere e posizione geografica, consente di mostrare le inserzioni solo alle persone che sono più propense ad essere interessate alla App in questione.
- Ottimizzazione del budget e delle offerte: Impostare un budget giornaliero per le tue campagne pubblicitarie e scegliere di pagare per ogni installazione (CPI) o per ogni tocco (CPT) nell’inserzione. Puoi anche impostare offerte per le parole chiave specifiche per ottenere una migliore posizione nei risultati di ricerca.
- Monitoraggio delle prestazioni: Apple Search Ads Advanced offre strumenti per monitorare le prestazioni delle tue campagne pubblicitarie. Potrai visualizzare metriche come il numero di impressioni, i clic, le conversioni e il costo per installazione. Questi dati sono molto importanti e consentono di valutare l’efficacia della tua strategia pubblicitaria e apportare eventuali ottimizzazioni necessarie.
È importante notare che Apple Search Ads Advanced richiede un investimento finanziario per l’esecuzione delle campagne pubblicitarie. È consigliabile fare una ricerca adeguata sulle best practice di ASO e valutare attentamente il budget e gli obiettivi di marketing prima di utilizzare questa piattaforma.
Apple Search Ads Basic
Apple Search Ads Basic è una forma semplificata di pubblicità offerta da Apple per promuovere le app all’interno dell’App Store. Si tratta di una soluzione più accessibile rispetto ad Apple Search Ads Advanced, con un processo di configurazione e gestione più semplice.
Ecco alcuni punti chiave da considerare su Apple Search Ads Basic:
- Facilità di utilizzo: Apple Search Ads Basic è progettato per essere facile da usare anche per gli sviluppatori meno esperti. Il processo di configurazione è semplificato e richiede meno passaggi rispetto ad Apple Search Ads Advanced.
- Strumenti di ricerca delle parole chiave: Puoi selezionare le parole chiave pertinenti per le quali desideri che la tua app venga mostrata come risultato di ricerca. Apple fornisce strumenti di ricerca delle parole chiave per aiutarti a identificare le parole chiave rilevanti per la tua app.
- Pagamento per clic: Con Apple Search Ads Basic, è possibile pagare solo quando un utente fa clic sulla tua inserzione. Non ci sono costi aggiuntivi associati agli installazioni dell’app. Questo modello di pagamento ti consente di controllare meglio il tuo budget pubblicitario.
- Budget giornaliero fisso: Apple Search Ads Basic richiede di impostare un budget giornaliero fisso per le tue campagne. Una volta raggiunto il budget, le tue inserzioni non verranno più mostrate per il resto della giornata. Questo aiuta a garantire che il tuo budget pubblicitario sia gestito in modo efficace.
- Monitoraggio delle prestazioni: Puoi monitorare le prestazioni delle tue campagne pubblicitarie attraverso il pannello di controllo di Apple Search Ads Basic. Puoi visualizzare metriche come il numero di impressioni, i clic e il costo per clic. Questi dati ti consentono di valutare l’efficacia delle tue inserzioni e apportare eventuali ottimizzazioni necessarie.
Apple Search Ads Basic è una buona opzione per gli sviluppatori che desiderano iniziare con la pubblicità sull’App Store in modo semplice e conveniente. Sebbene offra meno funzionalità rispetto ad Apple Search Ads Advanced, può comunque aiutarti a migliorare la visibilità della tua app e a raggiungere un pubblico più ampio.
Tra Apple App Store e Google Play Store, esistono differenze significative nel processo di pubblicazione delle app, che possono influenzare la tua esperienza come sviluppatore e la disponibilità dell’app per gli utenti.
Differenze ASO tra Android e Apple
Google Play Store – Aggiornamenti in Tempo Reale e Velocità
Google Play Store offre un vantaggio in termini di velocità e flessibilità nella pubblicazione delle app. Puoi pubblicare aggiornamenti e apportare modifiche praticamente in tempo reale. Questo significa che puoi rispondere rapidamente alle esigenze degli utenti e migliorare la tua app senza dover attendere lunghi tempi di revisione.
Apple App Store – Processo di Revisione Attento
D’altra parte, Apple App Store richiede un processo di revisione più attento. Quando invii la tua app per la pubblicazione, devi aspettare solitamente fino a 24 ore per ottenere l’approvazione. Durante questo periodo, il team di revisione esaminerà attentamente gli aspetti tecnici, di contenuto e di progettazione dell’app per garantire una maggiore qualità e sicurezza dell’esperienza dell’utente.
Valutazione delle App dopo la Pubblicazione
Una volta pubblicata, su Google Play Store le app vengono generalmente valutate dopo la pubblicazione, consentendoti di ottenere rapidamente il feedback degli utenti e migliorare il prodotto in base alle loro opinioni. Dall’altro lato, sull’Apple App Store, la valutazione potrebbe iniziare fin dalla pubblicazione, poiché l’approvazione della revisione può influenzare la visibilità e la posizione dell’app nei risultati di ricerca.
Algoritmi di Ranking e Importanza delle Parole Chiave
Entrambi gli store utilizzano sofisticati algoritmi di ranking per mostrare le app nei risultati di ricerca. Google Play Store adotta un algoritmo simile a quello di Google, prendendo in considerazione tutti gli elementi testuali dell’app, inclusi il nome, la descrizione e il contenuto per determinare il posizionamento.
L’Apple App Store, invece, fornisce un campo specifico dove puoi inserire le parole chiave rilevanti. Tieni presente che alcune parole chiave potrebbero essere automaticamente ottenute dai concorrenti o dalla categoria di appartenenza. Evita però di ripetere le parole chiave nel titolo e nel campo dedicato, in quanto ciò potrebbe avere un effetto negativo sul posizionamento dell’app.
Fattori di ranking di Apple App Store:
- Nome dell’applicazione
- URL dell’app
- Sottotitolo dell’app
- Campo parole chiave
- Acquisti in-app
- Valutazioni e recensioni
- Aggiornamenti
- Download e engagement
Fattori di ranking di Google Play Store:
- Nome dell’applicazione
- Descrizione dell’app
- Backlink
- App Indexing
- Acquisto in-app
- Valutazioni e recensioni
- Aggiornamenti
- Download e coinvolgimento
Foto di Fahim Muntashir su Unsplash
The post Come creare un’App di successo first appeared on Oimmei Digital Consulting.
]]>The post TypeScript: altri 5 trucchi per lo sviluppo first appeared on Oimmei Digital Consulting.
]]>Beh, noi sì. Parecchie volte, in effetti. Abbastanza da farmi chiedere se esista uno strumento migliore per sviluppare e mantenere certe applicazioni. Qualcosa che renda più semplice trovare errori con la gestione e l’utilizzo delle strutture dati, per esempio.
Per fortuna, la risposta è sì, e questo strumento è TypeScript! Estensione open source di JavaScript sviluppata principalmente da Microsoft, TypeScript aggiunge al linguaggio di programmazione preferito dei browser web molti nuovi strumenti e funzionalità, in particolare la tipizzazione statica, per rendere i progetti più robusti e facili da mantenere.
Molto probabilmente tutto questo lo sapete già, soprattutto se frequentate questo blog. Non solo per l’incredibile diffusione che ha raggiunto TypeScript negli ultimi anni, ma anche perché proprio su queste pagine era già uscito un mio articolo in cui presentavo alcune interessanti funzionalità di questo linguaggio. Avevo ipotizzato che prima o poi potesse uscire un sequel, e, puntuale come un errore “Cannot read property of undefined” in un’applicazione JavaScript, eccolo qua.
Ripartiamo subito, allora. Cinque paragrafi, cinque strumenti più o meno noti di TypeScript che potrebbero sorprendervi, con esempi e link al playground ufficiale per la versione 5.1.
Tuple
Questo è molto semplice, ma credo comunque che per qualcuno sarà una novità.
Chiunque abbia lavorato con TypeScript sa come tipizzare staticamente gli array: è sufficiente definire il tipo del singolo elemento, e aggiungere le parentesi quadre dopo di esso.
const numberArray: number[] = [];
// Validi:
numberArray.push(1);
numberArray.push(2);
// Non valido:
numberArray.push("string");
La cosa non altrettanto ovvia è che è possibile utilizzare le definizioni di tipo anche per creare in modo molto semplice delle tuple – già menzionate nel primo articolo -, o ennuple se preferite, ovvero strutture dati formate da una combinazione ordinata di elementi. Ecco un esempio di combinazione formata da tre numeri.
const numberArray: number[] = [];
// Validi:
numberArray.push(1);
numberArray.push(2);
// Non valido:
numberArray.push("string");
Il vantaggio delle tuple è che, come si vede dallo snippet di codice, la tipizzazione statica del compilatore TypeScript andrà a validare anche la cardinalità degli elementi, e non soltanto il loro tipo, assicurandoci quindi che la struttura dati contenga sempre tutti e soli gli elementi che ci aspettiamo.
Le tuple hanno molte applicazioni nei progetti software. In React, ad esempio, sono molto utili per definire variabili di stato che raccolgono in una sola semplice struttura dati più valori strettamente legati fra loro, così da poterla leggere e aggiornare senza rendere lo stato del relativo componente troppo ingombrante e verboso, soprattutto con gli hook.
A questo proposito, vale la pena di specificare che le tuple possono contenere dati eterogenei di qualsiasi tipo, anche complessi – incluse altre tuple, se volete metterci un po’ di creatività!
interface ResponseBody {
title: string
content: string
}
// Questa tupla contiene un codice HTTP, un
// messaggio di risposta e il body di risposta.
const apiResponse: [number, string, ResponseBody] = [
200,
"success",
{
title: "Titolo",
content: "Contenuto",
},
];
// Recupero i singoli elementi tramite destructuring
// (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment).
const [statusCode, message, body] = apiResponse;
console.log(statusCode);
console.log(message);
console.log(body);
Utility type: Readonly e NonNullable
Utility type! Ve li ricordate? Avevo già presentato un paio di questi costrutti modificatori di tipo nell’articolo precedente. Oggi ne vediamo altri due, spesso ignorati ma non per questo poco utili.
Readonly è un utility type che, preso un tipo, lo trasforma nel suo corrispondente in sola lettura. Nel caso dell’interfaccia per un oggetto, ad esempio, questo utility type permette di modificare quella interfaccia in modo che nessuna delle proprietà dell’oggetto possa essere riassegnata dopo la creazione.
// Interfaccia per un oggetto con ID e titolo.
interface SomeInterface {
id: number
title: string
}
// Oggetto SomeInterface:
const someObject: SomeInterface = {
id: 1,
title: "Titolo",
};
// Oggetto SomeInterface in sola lettura:
const someReadonlyObject: Readonly<SomeInterface> = {
id: 2,
title: "Titolo in sola lettura",
};
// Valido:
someObject.title = "Altro titolo";
// Non valido:
someReadonlyObject = "Altro titolo ancora";
Questa funzionalità può sembrare relativamente inutile a prima vista, ma pensate a quante volte si ha a che fare con valori che dovrebbero restare immutabili: oggetti che contengono configurazioni di qualche tipo, lo stato di un componente React, lo stato di uno store Redux o tutte quelle librerie che si basano sulla comparazione standard di JavaScript per scatenare determinati effetti nell’applicazione. Grazie a Readonly, è il compilatore stesso che può aiutarvi a gestire questi valori nel modo corretto, lanciando un errore quando tentate di assegnare una variabile che non dovrebbe essere riassegnata. È come un const, ma che va più in profondità!
NonNullable è un utility type che esclude da uno union type i tipi null o undefined. Credo che questo sia abbastanza autoesplicativo: utile quando un certo tipo, come quello della proprietà di un’interfaccia, prevede la possibilità che un valore sia vuoto, ma abbiamo bisogno di inizializzare una nuova variabile che invece deve essere valorizzata.
interface SomeInterface {
// In questa interfaccia, value può essere vuoto.
value: number | null | undefined
}
// Inizializzo esternamente una variabile da usare come
// value, ma stavolta voglio che sia valorizzata.
// Valido:
const val1: SomeInterface["value"] = null;
// Non valido:
const val2: NonNullable<SomeInterface["value"]> = null;
// Valido:
const val3: NonNullable<SomeInterface["value"]> = 10;
Generics: default, vincoli, condizioni
Per chi ha utilizzato linguaggi di programmazione come Java o C# – noto anche come Microsoft Java -, i generics non hanno bisogno di presentazioni. Per chiunque invece avesse ancora un po’ della propria sanità mentale, i generics permettono di creare componenti software che possono accettare una varietà di tipi diversi, dove il tipo specifico sarà fornito da chi utilizza il componente stesso, pur mantenendo tutti i vantaggi della tipizzazione statica.
interface SomeInterface {
// In questa interfaccia, value può essere vuoto.
value: number | null | undefined
}
// Inizializzo esternamente una variabile da usare come
// value, ma stavolta voglio che sia valorizzata.
// Valido:
const val1: SomeInterface["value"] = null;
// Non valido:
const val2: NonNullable<SomeInterface["value"]> = null;
// Valido:
const val3: NonNullable<SomeInterface["value"]> = 10;
La documentazione ufficiale parla estensivamente dei generics, per cui vi consiglio di dare un’occhiata là se vi servisse un’introduzione più rigorosa. Qui mi limiterò a citare alcune interessanti funzionalità a tema.
Per esempio: i generics si possono rendere opzionali fornendo un valore di default nella dichiarazione del componente, come con i parametri di una funzione. Se nessun tipo è specificato quando il componente viene utilizzato, il compilatore prenderà quello di default.
// string è il tipo di default per questa interfaccia.
interface GenericInterface<T = string> {
param: T
}
// Validi:
const value1: GenericInterface = {
param: "stringa"
}
const value2: GenericInterface<number> = {
param: 42
}
// Non valido: TypeScript assume che param sia di tipo stringa.
const value3: GenericInterface = {
param: 42
}
Questa funzionalità può rivelarsi utile per introdurre l’uso dei generics in un componente che al momento non ne ha, oppure per aggiungerne di nuovi, senza intaccare la sua retrocompatibilità.
Attenzione però: specificare un tipo di default non significa mettere un vincolo a quali tipi possano essere specificati sul componente. Il tipo fornito al momento dell’uso, infatti, potrebbe anche essere completamente diverso da quello di default, come visto sopra con number e string.
Ecco perché sarebbe sbagliato scrivere questo.
// Un'interfaccia della nostra applicazione.
interface SomeInterface {
id: number
name: string
}
// Funzione che usa un tipo generico, con l'interfaccia come default.
function someFunction<T = SomeInterface>(param: T): void {
// Non valido: non c'è garanzia che T e SomeInterface saranno compatibili.
console.log(param.name);
}
Per queste situazioni, è possibile imporre un vincolo al tipo che potrà essere accettato dal componente con extends, che può anche essere combinato con un tipo di default.
// Un'interfaccia della nostra applicazione.
interface SomeInterface {
id: number
name: string
}
// Funzione che usa un tipo generico che estende SomeInterface.
function someFunction<T extends SomeInterface = SomeInterface>(
param: T
): void {
// Valido: qualsiasi tipo sia T, sarà
// un'estensione di SomeInterface.
console.log(param.name);
}
// Non valido: il tipo non è compatibile.
someFunction<number>(42);
Per casi particolarmente complessi, è possibile anche usare delle condizioni per modificare la tipizzazione statica di altre parti del componente a partire dai generics. Un esempio classico: mettiamo di avere un componente che gestisce un valore, e questo valore può essere un singolo elemento così come un array di elementi.
Con i generics, possiamo gestire il tutto con una sola interfaccia:
- definiamo un’interfaccia con due tipi generici, il tipo del valore T e un tipo Multiple vincolato su un booleano;
- creiamo nell’interfaccia le proprietà value e onChange, rispettivamente valore e callback per quando il valore cambia;
- poniamo una condizione per il tipo delle proprietà in modo che cambi a seconda del tipo fornito per Multiple, sempre con extends.
Ecco il risultato.
// Multiple vincolato su boolean, non multiplo come default.
interface ComponentProps<T, Multiple extends boolean = false> {
// Il valore è un singolo elemento oppure un array.
value: Multiple extends false ? T : T[]
// onChange ha come parametro un singolo elemento oppure un array.
onChange: (newValue: Multiple extends false ? T : T[]) => void
}
// Oggetto per il caso singolo (lascio il default su Multiple):
const singleValueComponentProps: ComponentProps<string> = {
value: "Sono una singola stringa!",
onChange: (newValue) => {
console.log(
"Questo log stamperà sempre TRUE:",
typeof newValue === "string"
);
},
};
// Oggetto per il caso multiplo:
const multipleValueComponentProps: ComponentProps<string, true> = {
value: ["Sono", "un", "array", "di", "stringhe", "ora!"],
onChange: (newValue) => {
console.log(
"Posso usare i metodi di un array, perché newValue è un array:"
);
newValue.forEach((currentValue) => console.log(currentValue));
},
}
Type narrowing: type predicate
Dopo il primo articolo, torniamo a parlare di type narrowing, questa volta facendo un po’ più di giustizia a questa importantissima funzionalità.
La scorsa volta, parlando delle discriminated union, avevo solo brevemente menzionato l’argomento del type narrowing, dicendo in genere che si tratta del meccanismo con cui TypeScript riesce a dedurre, dalla tipizzazione che definiamo e dal flusso della nostra applicazione, quale tipo avrà una specifica variabile a runtime, così da presentarci gli errori appropriati durante la compilazione. Quello che non avevo detto è quanto dannatamente potente e onnipresente sia questo meccanismo nelle applicazioni TypeScript, e quanto spesso lo utilizziamo senza nemmeno rendercene conto.
Pensiamo a una funzione con un parametro che può essere una stringa oppure un numero. Se riceviamo una stringa, vogliamo stampare la sua lunghezza; se invece riceviamo un numero, vogliamo stamparne il valore in notazione puntata. La nostra conoscenza di JavaScript ci porta naturalmente a scrivere del codice come questo, usando l’operatore typeof.
function someFunction (value: string | number): void {
if (typeof value === "string") {
// Stampo la lunghezza:
console.log("Lunghezza della stringa:", value.length);
} else {
// Stampo il valore:
console.log("Valore:", value.toFixed());
}
}
Molto semplice, vero? Eppure, diverse cose tutt’altro che banali stanno succedendo sotto la superficie di questo snippet.
All’inizio della funzione, abbiamo indicato che il parametro value può essere una stringa oppure un numero, tramite uno dei nostri adorabili union type. Ma, nei due rami dell’if, stiamo usando delle funzionalità non comuni a questi due tipi: nel ramo then usiamo length, proprietà che non esiste nel tipo number, mentre nel ramo else usiamo toFixed, metodo che non esiste nel tipo string.
Se proviamo a eliminare l’if, vediamo che entrambi i suoi rami restituiscono giustamente un errore.
function someFunction (value: string | number): void {
// Stampo la lunghezza:
console.log("Lunghezza della stringa:", value.length);
// Stampo il valore formattato:
console.log("Valore:", value.toFixed());
}
Nella prima versione, però, TypeScript non segnala nessuna anomalia. Cosa c’è sotto?
La risposta sta proprio nel type narrowing. TypeScript esamina il nostro codice e, dagli operatori che usiamo e dal flusso dell’applicazione, si rende conto che in determinati punti dell’esecuzione un certo valore avrà un tipo più specifico rispetto a quello che abbiamo dichiarato.
L’operatore typeof, ad esempio, costituisce quello che si chiama una type guard, ovvero un operatore di controllo speciale che ha effetto sul tipo che TypeScript deduce per un certo valore. Ecco perché la prima versione della funzione sopra non restituisce errori: partendo dallo union type string | number, TypeScript vede la condizione dell’if e capisce non soltanto che nel ramo then value sarà certamente di tipo string, ma anche che nel ramo else value sarà per esclusione di tipo number.
Il type narrowing è cruciale per le applicazioni TypeScript, e si applica a un gran numero di costrutti diversi: i typeof, ma anche i confronti, gli assegnamenti, operatori come in e instanceof, negli if, negli switch…
Ma voi non siete qui per lunghe spiegazioni sul funzionamento di TypeScript. Voi volete qualche dritta su quelle funzionalità che potete usare nel vostro codice e raccontare alle feste per ottenere credito, rispetto e ammirazione dai vostri amici, e io vi accontento subito.
(Nota: la conoscenza di quanto spiegato di seguito potrebbe non farvi effettivamente ottenere credito, rispetto e ammirazione dai vostri amici. L’autore dell’articolo declina ogni responsabilità riguardo la scarsa riuscita della vostra vita sociale.)
Ci sono molti casi in cui sfruttare il type narrowing non è così banale. Certo, finché si parla di tipi primitivi come stringhe e numeri, oppure di utility built-in come Date, allora è tutto molto semplice, ma… se ci fosse bisogno di lavorare con interfacce definite da noi?
Tenete a mente che le interfacce TypeScript hanno un piccolo grande problema: non esistono a runtime. In effetti, non esistono e basta, dato che le interfacce al momento non esistono in JavaScript. Sono un aiuto per il compilatore per rilevare errori di tipo statici, ma vengono eliminate nel corso della compilazione. Quindi no, non possiamo semplicemente usare instanceof come faremmo con le interfacce di altri linguaggi orientati agli oggetti; dobbiamo metterci un po’ di impegno in più.
Un caso tipico: abbiamo un’interfaccia SomeInterface, una seconda interfaccia SomeExtension che estende la prima e una funzione che prende oggetti di tipo SomeInterface. Se l’oggetto che riceviamo ha tipo SomeExtension, vogliamo fare delle operazioni supplementari all’interno della funzione. Peccato che l’operatore in non basti a convincere TypeScript delle nostre buone intenzioni.
interface SomeInterface {
id: number
title: string
}
interface SomeExtension extends SomeInterface {
description: string
content: string
otherFields: Record<string, any>
}
function someFunction (obj: SomeInterface): void {
// Stampo tutte le proprietà.
// Validi:
console.log(obj.id);
console.log(obj.title);
if ("description" in obj) {
// L'operatore in ci permette di accedere a description...
console.log(obj.description);
// ...ma non basta a far riconoscere obj
// come oggetto di tipo SomeExtension.
console.log(obj.content);
console.log(obj.otherFields);
}
}
(Fino a TypeScript 4.8, avremmo avuto un errore anche per l’accesso a description. Nella versione 4.9 c’è stata qualche modifica al type narrowing, che permette di accedere in sicurezza al campo specificamente testato con in, anche se il tipo dedotto sarà unknown.)
Quello che dobbiamo fare qui è far capire a TypeScript che il nostro accesso alle proprietà dell’estensione è giustificato, o, se preferite, che stiamo usando queste proprietà solo quando obj è effettivamente di tipo SomeExtension. Per fortuna, questo è possibile con i type predicate.
In sostanza, i type predicate ci permettono di definire delle type guard personalizzate, con condizioni arbitrariamente complesse, che garantiscono a TypeScript che in un certo blocco della nostra applicazione una determinata variabile sia di un certo tipo – proprio come l’operatore typeof, ma con una logica interamente definita da noi.
Creiamo una funzione isSomeExtension, che prende in ingresso un parametro di tipo SomeInterface e restituisce un type predicate che stabilisce che il parametro in ingresso è di tipo SomeExtension. Nel body, la funzione deve esaminare il parametro e restituire true se il predicato in uscita è valido, false altrimenti.
Infine, usiamo quella funzione nella condizione di someFunction.
interface SomeInterface {
id: number
title: string
}
interface SomeExtension extends SomeInterface {
description: string
content: string
otherFields: Record<string, any>
}
function isSomeExtension (value: SomeInterface): value is SomeExtension {
// Se value contiene description, è di tipo SomeExtension.
return "description" in value;
}
function someFunction (obj: SomeInterface): void {
// Stampo tutte le proprietà.
// Validi:
console.log(obj.id);
console.log(obj.title);
if (isSomeExtension(obj)) {
// Validi: obj è di tipo SomeExtension in questo punto del codice.
console.log(obj.description);
console.log(obj.content);
console.log(obj.otherFields);
}
}
Tutto corretto!
Un appunto importante in chiusura di questo lungo paragrafo: tenete conto che con i type predicate stiamo praticamente “saltando” i controlli di tipo che TypeScript ci offre, e che il compilatore si fiderà completamente di noi per quanto riguarda il funzionamento della type guard. Ciò significa che dobbiamo fare molta attenzione a scrivere la funzione che controlla il tipo: se sbagliamo qualche condizione nel body, ce ne renderemo conto solo dai bug a runtime!
Function overload
Chi proviene da linguaggi come Java conoscerà il method overloading: si tratta di quella funzionalità che permette di specificare, all’interno di una classe o di un’interfaccia, più metodi con lo stesso nome e diversi insiemi di parametri – per esempio un numero diverso di parametri, oppure parametri di tipo differente.
Forse non tutti sanno che una funzionalità molto simile esiste anche in TypeScript, e può essere davvero utile in certe situazioni. Sto parlando del function overload, utilizzabile sia sulle funzioni che sui metodi di una classe.
una funzionalità molto simile esiste anche in TypeScript, e può essere davvero utile in certe situazioni. Sto parlando del function overload, utilizzabile sia sulle funzioni che sui metodi di una classe.
Il funzionamento è sostanzialmente lo stesso del method overloading, ma con una differenza importante: mentre il method overloading permette di dichiarare effettivamente più metodi con diversi body, nel function overload l’effettiva funzione con il body deve essere una sola, ma possono essere specificate diverse signature per le varie versioni. Ciò significa che la funzione dovrà essere scritta in modo da essere compatibile con tutte le signature, altrimenti avremo un errore di tipo.
// Signature diverse:
function someFunction (param: number): number;
function someFunction (param: string): string;
// Implementazione della funzione:
function someFunction (
param: number | string
): number | string {
if (typeof param === "number") {
console.log("È un numero!");
} else {
console.log("È una stringa!");
}
return param;
}
const val1 = someFunction(42);
const val2 = someFunction(
"Addio, e grazie per tutto il pesce"
);
Questo vincolo può far sembrare il function overload limitante e di scarsa utilità, ma bisogna tenere conto di un vantaggio importante: dichiarando la funzione in questo modo, TypeScript sarà in grado di assegnare correttamente, a seconda dei parametri in ingresso, il tipo del valore che viene restituito. In altre parole, non dovremo preoccuparci di fare manualmente un ulteriore type narrowing su quello che ci restituisce la nostra funzione.
Per dimostrare le potenzialità di quanto detto, aggiungiamo un paio di righe allo snippet di prima.
// Signature diverse:
function someFunction (param: number): number;
function someFunction (param: string): string;
// Implementazione della funzione:
function someFunction (
param: number | string
): number | string {
if (typeof param === "number") {
console.log("È un numero!");
} else {
console.log("È una stringa!");
}
return param;
}
const val1 = someFunction(42);
const val2 = someFunction(
"Addio, e grazie per tutto il pesce"
);
// Validi:
console.log(val1.toFixed());
console.log(val2.length);
In questo esempio, trattiamo val1 e val2 rispettivamente come un numero e una stringa. Il motivo per cui possiamo farlo senza ottenere errori è proprio il fatto che abbiamo utilizzato il function overload: TypeScript è in grado di dire che someFunction restituirà un numero quando riceve un numero e una stringa quando riceve una stringa.
Ecco come sarebbero cambiate le cose se non avessimo usato il function overload.
function someFunction (
param: number | string
): number | string {
if (typeof param === "number") {
console.log("È un numero!");
} else {
console.log("È una stringa!");
}
return param;
}
const val1 = someFunction(42);
const val2 = someFunction(
"Addio, e grazie per tutto il pesce"
);
// Non validi: TypeScript non è in grado
// di dedurre il valore delle variabili.
console.log(val1.toFixed());
console.log(val2.length);
// Dobbiamo fare type narrowing manualmente:
if (typeof val1 === "number") {
console.log(val1.toFixed);
}
if (typeof val2 === "string") {
console.log(val2.length);
}
Già questo semplicissimo esempio è diventato molto più verboso; potete immaginare l’impatto che può avere la cosa in un codice più complesso e realistico.
Un’applicazione molto valida per il function overload è quando abbiamo una funzione che può operare indifferentemente su un singolo valore o su un array di valori.
function multiplyValue(
value: number,
multiplyBy: number,
): number;
function multiplyValue(
value: number[],
multiplyBy: number,
): number[];
// Moltiplica un valore o ogni valore
// in un array per un operando.
function multiplyValue(
value: number | number[],
multiplyBy: number,
): number | number[] {
if (Array.isArray(value)) {
const result = [];
for (let i = 0; i < value.length; i++) {
result.push(value[i] * multiplyBy);
}
return result;
} else {
return value * multiplyBy;
}
}
const singleValue = multiplyValue(11, 2);
const arrayOfValues = multiplyValue(
[1, 1, 2, 3, 5],
5
);
// singleValue è un number:
console.log(singleValue.toFixed());
// arrayOfValues è un array di number:
arrayOfValues.forEach((item) => {
console.log(item.toFixed())
});
(Notare fra l’altro come anche Array.isArray sia una type guard valida.)
Nessuna type guard necessaria al di fuori della funzione! Esistono forse parole più dolci di “posso scrivere meno codice”?
Conclusione
Anche questo secondo articolo sulle funzionalità di TypeScript è finito (non hai ancora letto la prima parte? Che aspetti?!). Spero che questi paragrafi siano riusciti a farvi scoprire qualcosa di nuovo, o magari a farvi soffermare su qualche aspetto del linguaggio che non avevate mai considerato prima.
Di nuovo, se avete qualcuno dei vostri strumenti segreti per TypeScript che vi piacerebbe condividere, non vedo l’ora di conoscerli. Uscirà mai un terzo articolo? Chissà!
Foto di Christopher Gower su Unsplash
The post TypeScript: altri 5 trucchi per lo sviluppo first appeared on Oimmei Digital Consulting.
]]>The post Intelligenza artificiale: il test di Turing è ancora affidabile? first appeared on Oimmei Digital Consulting.
]]>Secondo quanto riportato da Bloomberg, Il tradizionale test di Turing, originariamente concepito per distinguere il ragionamento umano da quello di un programma attraverso una serie di domande, ha perso la sua rilevanza nel contesto attuale, date le straordinarie capacità delle piattaforme di AI, molte delle quali sono liberamente accessibili. Questo è particolarmente evidente se consideriamo chatbot come ChatGpt o Google Bard, che sono in grado di generare testi e risposte coerenti e complesse. Pertanto, Suleyman propone di spostare l’attenzione verso nuovi test che siano in grado di valutare le diverse tipologie di intelligenza artificiale, anziché confrontarle direttamente con l’essere umano.
La proposta di Suleyman è quella di introdurre un moderno test di Turing che metta alla prova le capacità delle AI nell’affrontare una sfida più ampia: trasformare 100.000 dollari in 1 milione di dollari. In altre parole, un chatbot dovrebbe dimostrare di essere in grado di individuare opportunità commerciali, creare progetti per prodotti da vendere online e trovare i giusti produttori. Secondo Suleyman, entro due anni le AI saranno in grado di raggiungere queste capacità di ragionamento e sarà importante concentrarsi non solo su ciò che una macchina dice, ma su ciò che può effettivamente fare.
L’idea di Suleyman è affascinante e stimolante, ma solleva anche alcune importanti domande sulle conseguenze che ciò avrà sull’economia globale. Se i chatbot diventassero in grado di svolgere attività di business complesse e generare profitti significativi, ciò potrebbe portare a una rivoluzione nel modo in cui le imprese operano e interagiscono con il mercato. Potrebbe anche innescare un dibattito etico sulle implicazioni di una maggiore autonomia delle macchine e sul futuro del lavoro umano.
In conclusione, il Test di Turing potrebbe non essere più l’unico strumento affidabile per valutare l’intelligenza artificiale. L’evoluzione delle tecnologie ha reso necessario un nuovo approccio, come proposto da Suleyman, che ponga l’accento sulle capacità operative delle AI. Saremo quindi chiamati a riflettere sulle implicazioni di questa nuova frontiera e ad adattarci ai cambiamenti che essa comporterà. Il futuro dell’intelligenza artificiale è in continua evoluzione, e solo il tempo dirà quale sarà la prossima tappa nella sfida tra AI e mente umana.
Foto di Pixabay
The post Intelligenza artificiale: il test di Turing è ancora affidabile? first appeared on Oimmei Digital Consulting.
]]>The post Git per il controllo delle versioni first appeared on Oimmei Digital Consulting.
]]>Git è stato creato da Linus Torvalds nel 2005, il famoso sviluppatore del kernel Linux. Inizialmente, Torvalds si trovava ad affrontare problemi di gestione delle versioni durante lo sviluppo del kernel, utilizzando il sistema di controllo delle versioni esistente, chiamato BitKeeper. Quando BitKeeper non fu più disponibile gratuitamente per progetti open-source, Torvalds decise di creare un nuovo sistema da zero.
L’obiettivo principale di Git era quello di essere un sistema di controllo delle versioni distribuito, in cui ogni sviluppatore avesse una copia locale completa del repository, comprensiva di tutto il codice e della storia delle modifiche. Questo approccio consente agli sviluppatori di lavorare in modo indipendente e offline, senza dipendere da un server centralizzato. Inoltre, Git è estremamente veloce nel confrontare e unire le modifiche apportate da diversi sviluppatori.
Git è basato su alcuni principi chiave. La sua struttura dati fondamentale è un grafo aciclico diretto (DAG), in cui ogni commit rappresenta uno stato del progetto. Ogni commit è identificato da un hash che lo rende unico e immutabile. Git utilizza il concetto di “branch” per consentire lo sviluppo parallelo e la creazione di nuove funzionalità in modo isolato. Inoltre, supporta il concetto di “merge” per unire i branch e “rebase” per applicare i commit in un ordine diverso.
Negli anni, Git è diventato lo standard de facto per il controllo delle versioni nella comunità dello sviluppo software. È ampiamente utilizzato da aziende, progetti open-source e sviluppatori individuali in tutto il mondo. La sua flessibilità, la sua velocità e la sua potenza lo rendono una scelta ideale per la gestione dei progetti di qualsiasi dimensione.
In conclusione, Git è un sistema di controllo delle versioni distribuito che ha cambiato il modo in cui gli sviluppatori gestiscono il codice sorgente. Con la sua storia affascinante e la sua efficacia comprovata, Git è diventato uno strumento indispensabile per chiunque si occupi di sviluppo software.
The post Git per il controllo delle versioni first appeared on Oimmei Digital Consulting.
]]>The post SQL e ordine di esecuzione delle query first appeared on Oimmei Digital Consulting.
]]>Per interagire con il database si utilizzano le “query”.
La query è il costrutto più importante e più usato del linguaggio SQL: questa è una funzione che permettere di interrogare il database in modo da ottenere delle informazioni ivi contenute filtrandole, a seconda delle esigenze, con l’introduzione di speciali costrutti e parole chiave.
Se scritta male una query può impiegare molto tempo e non dare i risultati sperati, per ottimizzarle è importante capirne l’ordine di esecuzione, questo schema ne riassume i capisaldi!
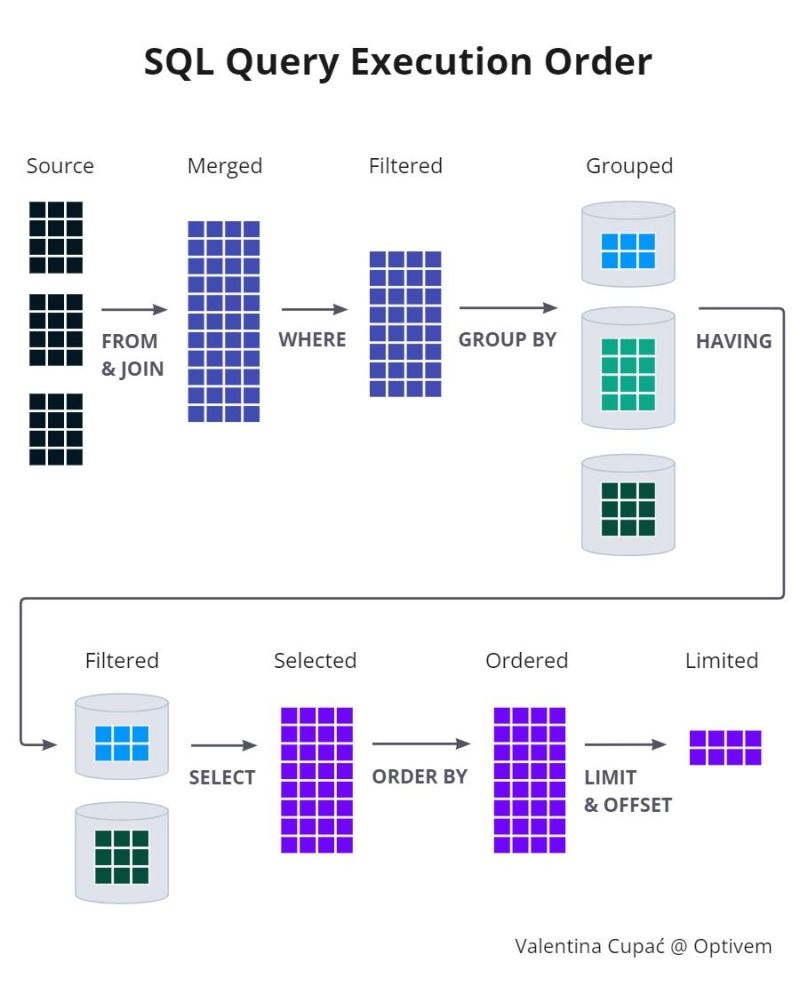
The post SQL e ordine di esecuzione delle query first appeared on Oimmei Digital Consulting.
]]>The post App Aziendale. Quali sono i motivi per sviluppare un’App? first appeared on Oimmei Digital Consulting.
]]>Qui di seguito sono riportati alcuni motivi per cui sviluppare un’applicazione può essere importante:
- Migliorare la visibilità dell’azienda: un’app per smartphone può aiutare a migliorare la visibilità dell’azienda e ad aumentare la consapevolezza del marchio tra il pubblico; un’app può aiutare a raggiungere un pubblico più ampio data la quantità in aumento delle persone connesse.
- Fidelizzare i clienti: sviluppare un’app può anche aiutare a fidelizzare i clienti esistenti in quanto n’app ben progettata può offrire ai clienti una migliore esperienza d’uso, un accesso più facile ai prodotti o ai servizi dell’azienda con promozioni esclusive e altre funzionalità utili.
- Aumentare le vendite: un modo efficace per aumentare le vendite dell’azienda può essere la creazione di un’app di e-commerce così da offrire ai propri clienti una comoda modalità di acquisto che può portare a una maggiore conversione delle vendite.
- Mantenere il passo con la concorrenza: per rimanere al passo con la concorrenza oggi necessitiamo di una app dato che la maggior parte delle aziende del settore ne hanno già una: non avere una propria app potrebbe lasciare l’azienda indietro rispetto alla concorrenza.
In definitiva, far sviluppare la propria app può essere un’ottima scelta per molte aziende, indipendentemente dal settore in cui operano. Tuttavia, è importante ricordare che lo sviluppo di un’app per i nostri device richiede tempo, risorse e competenze specifiche quindi, è importante scegliere un partner affidabile che possa così aiutare la propria azienda a raggiungere obiettivi di business personali e personalizzabili.
Foto di Onur Binay su Unsplash
The post App Aziendale. Quali sono i motivi per sviluppare un’App? first appeared on Oimmei Digital Consulting.
]]>